ExaGrid knows that deduplication is required, but how you implement it changes everything in the backup. Data deduplication reduces storage requirements and bandwidth for replication. However, if it is not implemented correctly, backups, restores and VM starts will be slowed down drastically and the backup window will get bigger with increasing amounts of data. This is due to the fact that data deduplication is very computationally intensive. You do not want to perform deduplication during the backup window, nor do you want to restore deduplicated data or boot from a pool.
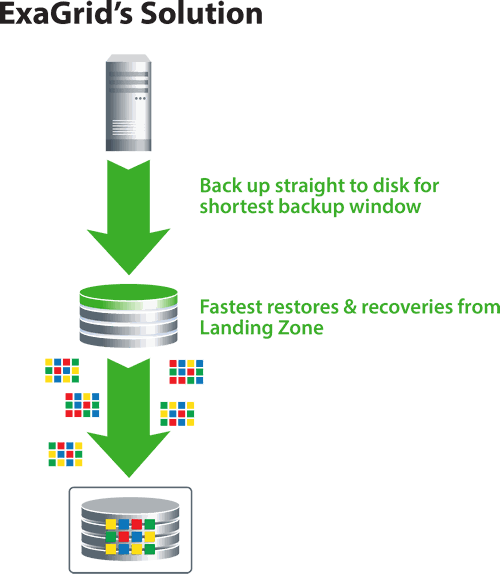
ExaGrid offers the best level of data deduplication and has implemented data deduplication so that backup performance is 6 times higher and recovery and VM boot performance up to 20 times higher than with other approaches. ExaGrid has a unique landing zone where backups can land directly on the hard drive without inline deduplication processing. Backups are fast and the backup window is short. Deduplication and off-site replication take place in parallel with the backups and never hinder the backup process because they are always of second order priority. ExaGrid calls this "adaptive deduplication".
Fastest backup / shortest backup window
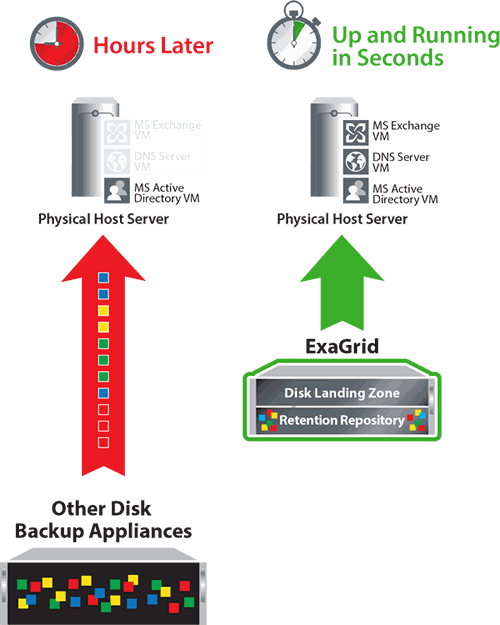
Because backups are written directly to the landing zone, the latest backups in their complete, non-duplicated form are ready for any requirement. Local restores, instant VM restores, backup copies, tapes, and all other requirements do not require rehydration and are as fast as the hard drive. For example, inline deduplication approaches do instant VM restores in seconds to minutes compared to hours that only store deduplicated data that needs to be re-hydrated for each request.
Fastest restores, restores, VM starts and tape copies
Scalability: fixed length backup window and data growth
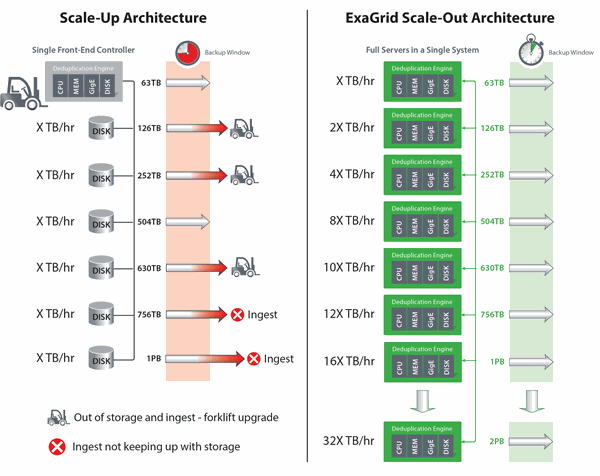
ExaGrid offers complete appliances (processor, memory, bandwidth and hard disk) in a scale-out system. As data grows, all resources are added, including additional landing zone, bandwidth, processor and memory, and hard drive capacity. The backup window remains fixed in length regardless of the data growth, which means that expensive upgrades of the forklift are not necessary. Unlike the inline scale-up approach, which requires you to guess the size of the front-end controller, the ExaGrid approach allows you to easily pay for your growth by adding the appropriate appliances, when your data grows. ExaGrid offers appliance models in various sizes, and appliances of all sizes and ages can be combined and matched in a single system, allowing IT departments to purchase computing power and capacity as needed. This evergreen approach also eliminates product aging.
Scale-up vs. Scale-out architecture in backup storage technologies
The Buyer's Guide to Storage for Backup
This Storage for Backup Buyer Guide provides insight into key features and cost drivers to consider when choosing a storage solution for backup. It examines how the capabilities of leading solutions help companies achieve their key short and long-term goals in terms of data protection, data recovery and costs. The manual is aimed at medium-sized IT executives with more than 50 TB of data who want to implement a new solution or improve their existing backup installation.
Storage for backup solutions must meet several important evaluation criteria, including the ability to provide:
1. Schnelle und effiziente Backup-Leistung für die Einhaltung von Backup-Fenstern
3. Skalierbarer Backup-Speicher, der mit wachsenden Daten wächst
4. Gesamtbetriebskosten im Voraus und im Laufe der Zeit
2019 Buyer Guide for Storage for Backup
Supported backup applications
ExaGrid supports a variety of backup applications, utilities, and database dumps. In addition, ExaGrid enables multiple approaches in the same environment. An organization can use a backup application for their physical servers, another backup application or utility for their virtual environment, and can also perform direct Microsoft SQL or Oracle RMAN database dumps - all on the same ExaGrid system. This approach enables customers to use the backup application and utilities of their choice, to use the best backup applications and utilities, and to select the right backup application and utility for each use case.
If you change backup applications in the future, the ExaGrid system will continue to work and protect your original investment.
ExaGrid supports many unique functions and interfaces, such as These include improved performance for Veritas Backup Exec GRT, AIR for Veritas NetBackup, OST for Veritas Backup Exec, and Veritas NetBackup, the integrated Veeam Data Mover for Veeam, Veeam SOBR support, Oracle RMAN Channels support, and many more.
Many backup applications perform software-based data deduplication. ExaGrid deduplication leverages backup software and adds additional deduplication to increase overall ratios, resulting in additional disk and bandwidth savings.
ExaGrid is the only solution that offers a unique landing zone that stores full copies of the latest backups of all backup applications, utilities, and direct database dumps, making restores, restores, and tape copies as fast as reading from disk.
Das ExaGrid-System unterstützt kostengünstige und skalierbare plattenbasierte Backups mit der Backup-Software Acronis® Backup & Recovery. ExaGrid unterstützt auch die Möglichkeit, Ihre Acronis Backup & Recovery-Backups auf einen zweiten Standort zu replizieren, um den Disaster Recovery-Schutz außerhalb des Standorts zu gewährleisten.
ExaGrid's unique approach enables all virtualized backup functions to be performed quickly, as ExaGrid maintains a full copy of the latest full VM backups in their complete, unduplicated form in an integrated landing zone, eliminating the need for time-consuming data rehydration for each request.
ExaGrid supports up to 16 large data centers in a cross protection group with a master hub and 15 locations.
Over 50% of ExaGrid customers removed the tape both on-site and off-site using an on-site ExaGrid system for local backups and restores, and then replicated to an ExaGrid in a second location as a second data center for disaster recovery.
Alle Dienstanbieter bieten die folgenden Vorteile für die DR außerhalb des Standorts:
● ExaGrid-Zielsysteme gehören einem Drittanbieter und werden von diesem betrieben. ● Es gibt zusätzliche Sicherheitsschichten für die Datenübertragung, die Datenzugriffssicherheit und die Sicherheit im Ruhezustand. ● Mit diesem Pay-as-you-use-Modell zahlen Unternehmen pro Monat nach GB.